
At Airbus Defence and Space Cyber, we aim to produce state-of-the-art quality softwares. This is always a challenge, in particular with maintenance contracts that can sometimes last over multiple decades. In order to maintain an optimal quality throughout the life of the software while facilitating the work for the teams that might follow one another, some of our teams have embraced modularity as a strategy to live up to these challenges. In this paper, our expert Charles Hymans will describe the techniques and coding style these teams have adopted to write modular code in C.
Modules
Left unchecked to the raw forces of entropy, any codebase will tend to grow into a big ball of mud. C compilers let us split the codebase into several files. That way, instead of dealing with an intimidating linear blob of globals, functions and instructions devoid of any topography, we can reason at a higher level of abstraction: the module. This strategy goes by many names: divide and conquer, modularize, compartimentalize, structure…
A module consists of two pieces:
- the header file with extension
.h, - the source file with extension
.c.
The header file describes the public interface of the module and is made available to its consumers. The source file contains the nitty-gritty implementation details themselves. The module’s internal complexity is hidden away (as long as it behaves as expected, that and unit testing are an entirely other story).
The interface and implementation files may themselves depend on other modules, which we tell the C preprocessor to include with the following syntax:
#include <stdbool.h>We have a few rules related to inclusions.
-
The alternative syntax of relative inclusion is forbidden:
#include "hello.h" -
Include of source files are forbidden:
#include <hello.c>
In that, we are consistent with a more general principle of ours: that of economy of means. In a sometimes somewhat Spartan way, we try to do without whenever we can. The goal here is to reduce code heterogeneity as much as possible, so that anyone can dive into any codebase from the company: individual developers’ idiosyncracies should be minimal. Given some requirements, there is only one possible program; a unique syntax for every semantics. That, of course, is an ideal that can never be reached in practice. It works as a useful signpost, an energizing utopia, if you will.
The C preprocessor being what it is, nothing prevents a header to be included twice, causing a compilation error. Header guards are the standard technique to circumvent this problem. It relies on the definition (#define) of a variable which signals the inclusion of the header. One downside of this technique is that one has to be wary to strictly follow a global nomenclature in order to avoid variable names clashes. So we prefer the more recent and more carefree directive:
#pragma onceAs an aside, note that we still need to set a nomenclature for global variable, function and type identifiers. Hence every identifier is prefixed with the full path to its module:
<package-name>_<module-name>_<function-name>However, since adherence to the nomenclature is not automatically checked by a tool, human errors may sometimes happen. The absence of user-defined namespaces in the C programming language is somewhat painful. It could perhaps make for a great improvement in a future version of the standard. Hopefully soon: industrial civilisation is running out of steam, litterally.
Hidden temporal coupling
Obsviouly, designing quality interfaces matters crucially. Function names should be carefully choosen and documented so that, ideally, it is possible to understand a piece of code without having to drill down into lower layers of dependent modules. The overall interface logic should be carefully thought in order to deliver maximum value with ease of use and minimal pitfalls. For instance we try our best to avoid hidden temporal couplings (see G31 in Clean code by Robert C Martin and also Singletons are Pathological Liars):
initialize();
process();Suppose swapping function process before initialize would break the code. Function process depends on function initialize. This is a temporal coupling. It is hidden because the programmer has no way of knowing, without reading the implementation of both functions (except sometimes from the function names). The root cause of hidden temporal coupling is some global state which acts as a channel between the two functions. It is largerly preferable to make this state apparent. It can now be required by function process as a proof function initialize was called first:
state_t* state = initialize();
process(state);Modules testability is a concern too.
For all these reasons, we adopt a data-oriented philosophy to modules. They are organized a bit like classes in object oriented languages:
- first the module’s state is declared as a structure,
- and defined as a type thanks to
typedef. allocfunctions allocate and initialize the state,- to be passed to any
processfunction as their first parameter, - and eventually disposed of thanks to the ad-hoc
freefunction. In addition, we enforce no more than one such module definition per file.
Following the single responsibility principle, modules are designed as tightly perimetered logical units. They should do only one thing. Whenever a module covers more than one functional aspect it is split. Then sometimes, even the meaning of one, can become a subject of debates. Questions arise such as, for instance: should logging or error reporting be outsourced or directly coded within each module?
Exemple
Let us now give a full-fledge exemple of a module written following the rules presented so far. I picked a well-known data-structure from chapter 10 of the notorious Introduction to Algorithms. First, let’s have a look at the header (file fifo.h):
#include <stdbool.h>
#include <stdlib.h>
#define N 100
typedef struct {
int content[N];
size_t first;
size_t last;
} fifo_t;
fifo_t *fifo_alloc(void);
void fifo_enqueue(fifo_t *this, int value);
int fifo_dequeue(fifo_t *this);
void fifo_free(fifo_t *this);So it’s an integer queue, implemented as a fixed ring buffer, of at most 99 elements. Before we dive into the implementation details, let’s first play around a bit (file main.c):
#include <fifo.h>
#include <stdlib.h>
#include <stdio.h>
int main(void) {
fifo_t *queue = fifo_alloc();
if (queue == NULL) {
return EXIT_FAILURE;
}
fifo_enqueue(queue, 1);
fifo_enqueue(queue, 2);
int value = fifo_dequeue(queue);
printf("Value from the queue: %d\n", value);
fifo_free(queue);
return EXIT_SUCCESS;
}We call the constructor of the queue and check the allocation does not fail. Then we enqueue two elements, dequeue one and print its value. Finally, we do not forget to free the data-structure. Pretty straight-forward stuff.
Let’s now have a look at the implementation:
#include <fifo.h>
#include <stdbool.h>
#include <stdlib.h>
fifo_t *fifo_alloc(void) {
fifo_t *this = malloc(sizeof(fifo_t));
if (this == NULL) {
return NULL;
}
this->first = 0;
this->last = 0;
return this;
}
void fifo_enqueue(fifo_t *this, int value) {
this->content[this->last] = value;
this->last = (this->last + 1) % N;
}
int fifo_dequeue(fifo_t *this) {
int result = this->content[this->first];
this->first = (this->first + 1) % N;
return result;
}
void fifo_free(fifo_t *this) {
free(this);
}The ring buffer consists of an array content of size N and two indices first and last which indicate the boundaries of the queue. Index last points to the free slot where the next element will be enqueued. Index first points to the slot with the first element of the queue. It is the element which will be dequeued next. Both indices grow without overflowing the buffer: their position is computed modulo the size of the array. When both indices are equal, the queue is empty. When index last is just one position (modulo N) before index first, the queue is full. This implies that the queue can only fill at most N-1 elements of its content buffer. Note that funnily, trying to dequeue an element from an empty queue will not fail. Rather, it will return some arbitrary value (which depends on the past life of the queue) and set the queue in a state where it is full. This is the kind of silent bugs which may be quite hard to hunt down.
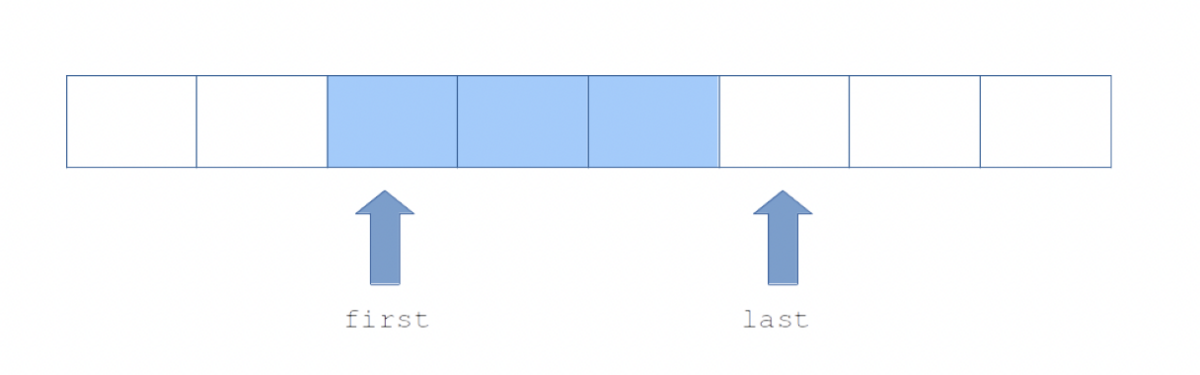
It’s alive!
Codebases can feel like creatures with life on their own. Code wants to grow. A function to check the emptiness of the queue is definitely missing from this module. In fact, even more functions are missing in order to be able to: check fullness, retrieve the element count, get a peek at the next element… For the time being let’s assume a consumer of the queue, in some distant portion of the codebase needs to check whether the queue is empty. Since the representation of the queue is transparently accessible, a check is quite easy to hack locally (file galaxy_far_away.c):
// somewhere in a galaxy far away...
if (queue->first != queue->last) {
int value = fifo_dequeue(queue);
...
}It is preferrable to take the time and extract this check as a static function:
static bool _is_empty(fifo_t *this) {
return (this->first == this->last);
}It would even be better to bring this function down into the fifo module. This would avoid potential code duplication. But maybe that is easier said than done. Maybe the consumer has access to the library in binary form only with no modification rights. Maybe requesting a new feature seems too much of a hassle. So far so good. At least it works.
Or so it seems, because things will now start to turn sour. Let’s imagine the queue implementation undergoes some modification. This is not radical, only the interpretation of index first changes: it now points one position before the first element of the queue.
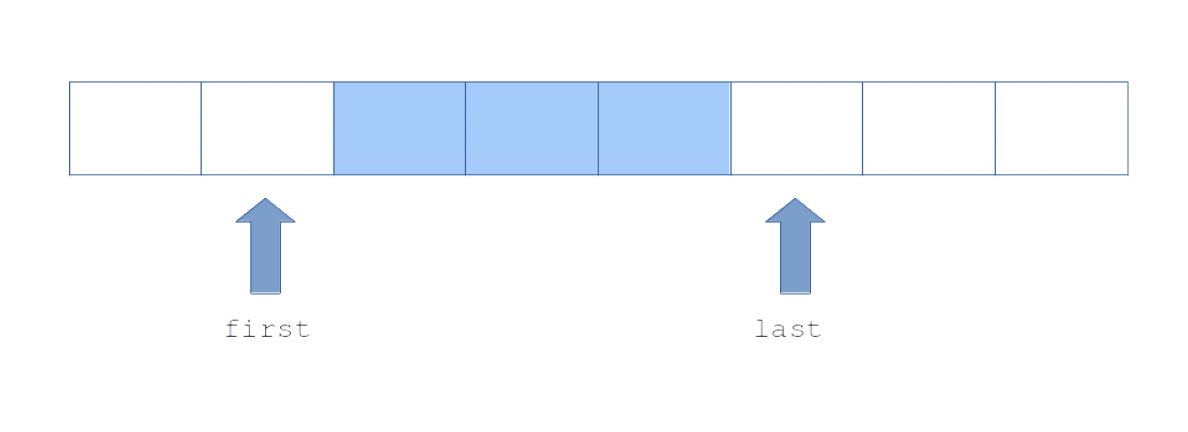
In the implementation, only the instructions that involve field first differ:
fifo_t *fifo_alloc(void) {
fifo_t *this = malloc(sizeof(fifo_t));
if (this == NULL) {
return NULL;
}
this->first = N - 1;
this->last = 0;
return this;
}
int fifo_dequeue(fifo_t *this) {
this->first = (this->first + 1) % N;
return this->content[this->first];
}Function fifo_dequeue looks slightly simpler: local variable result has dropped. It was needed to temporarily store the result, which had to be rerieved, before the update to index first. I know this does not look like a great incentive to take risks and change the implementation of a low-level data-structure, potentially relied upon by multiple consumers. I readily admit that this example may seem a bit contrived. However I chose it for concision of the argument. And similar situations may arise in real life with more complex data-structures and better motivations. Every time the meaning of a module’s data-structure changes, but the types stay the same: a NULL value is introduced, enum values are added, swapped or removed, negative integers are used, the nature of the invariant between fields changes…
In all these cases, any code which relied on the data-structure encoding may break without the compiler picking it up. You still have your next line of defenses: automatic tests (you do, right?). This is the case in our example too, where the check in galaxy_far_away.c would have to change to:
static bool _is_empty(fifo_t *this) {
size_t next = (this->first + 1) % N;
return (next == this->last);
}It would be nice to have the compiler ensure that:
- modules’ code is not scattered all around the place,
- code is not unnecessarily duplicated,
- and subtle bugs are not experienced whenever the nature of modules’ data invariants change.
Enter opaque structures.
Opaque structures, the missing piece of the puzzle
Consider incomplete structure types. We are going to make the most of this feature of the C language, in a way it was probably originally not intended for. The K&R and the first version of the C standard (C89), both motivate this construct to allow for the declaration of recursive structures.
To paraphrase C89, when a type specifier of the form struct identifier occurs before its content definition, then it is incomplete. The standard gives examples of both self-referential and mutually-referential structures, which I recall below:
struct tnode {
int count;
struct tnode *left, *right;
};
struct s1 { struct s2 *s2p; /*...*/ }; /* D1 */
struct s2 { struct s1 *s1p; /*...*/ }; /* D2 */Incomplete structure types are valid anywhere the size of the type is not needed. As we have just seen, this is the case when specifying the type of a pointer. Recall the function signatures of the queue module. They too only relied on the module’s structure type as a pointer. We can thus remove the definition of the structure content from the header:
#include <stdbool.h>
#include <stdlib.h>
typedef struct fifo fifo_t;
fifo_t *fifo_alloc(void);
void fifo_free(fifo_t *this);
void fifo_enqueue(fifo_t *this, int value);
int fifo_dequeue(fifo_t *this);And move it down behind the scene into the implementation:
#define N 100
struct fifo {
int content[N];
size_t first;
size_t last;
};The interface is now undeniably easier to read. It is not cluttered with unnecessary implementation details. It presents only what matters from the consumer’s perspective, an abstract data type.
This is how encapsulation can be hacked in C.
Benefits of opaque modules
Beyond a certain threshold in the amount of lines of code, modules become a necessity. They provide a technical means to achieve separation of concerns. They let us introduce meaningful abstractions to reason about the business problem. We can organize the codebase into layers of increasingly higher levels of abstraction. Thus making complexity more manageable. Modules can then be further classified into libraries.
Opaque structures improve the effectiveness of modules by ensuring information hiding both ways:
- when the implementation of a module changes without any modification to the interface, then the rest of the codebase can be left untouched,
- a module consumer can not introduce a bug by breaking some state invariant.
If we return to our running exemple, the code in a galaxy_far_away.c to check queue emptiness will not compile anymore because it tries to access the internal representation of the queue directly. This is an indication it should be moved down into file fifo.c, where it rightly belongs:
bool fifo_is_empty(const fifo_t *this) {
size_t next = (this->first + 1) % N;
return (next == this->last);
}This new function is then exported via the header, and will potentially benefit to every consumers of the queue:
bool fifo_is_empty(const fifo_t *this);We can now rely on the compiler to enforce all instructions which manipulate a given data-structure are localized. Unnecessary code duplication can thus be avoided, which is a major step forward towards DRY.
Note in passing, how we took this opportunity to improve the signature of the function by adding the const specifier. It indicates both to the compiler and the reader that the content of the instance passed as parameter this will not be modified.
Some programmers dislike opaque structures. Some argue that too much abstraction makes code harder to read. I have a difficult time understanding this argument objectively. This may be a matter of habits, tastes and inner wiring? Others would like to be able to allocate their objects on the stack to limit memory leaks. This makes sense. Experience shows, however, modules naturally enforce a rigorous well parenthesized allocation/deallocation pattern. This is further reinforced by unit testing suites run in consort with valgrind or clang AddressSanitizer and LeakSanitizer. The benefits seem to largely outweigh the drawbacks.
In some of our teams, opaque structures was made the default. There are admittedly some cases when structures should not be opaque. So far (more than a decade :), exemptions were made for pure data, immutable objects only. Some concrete examples come to mind: lists of results, or the entirely read-only structure that propagates configuration data throughout the program at initialization time.
Conclusion
In this blog post, the way some of the teams at Airbus Defence and Space Cyber write modules to handle large C codebase was presented. The C programming language feature of incomplete structure types is leveraged to render modules opaque. That way, the compiler can be made to guarantee encapsulation. This was also the opportunity to present some important coding rules and tools.
These practices applied, day after day, with care and patience lower maintenance costs, increase robustness and ultimately serve the long time interest of our customers best. Despite a somewhat popular misconception these seemingly time-consuming practices all contribute to gradually build up productivity too.
A complementary strategy towards scalabity was not addressed here: it relies on breaking down a large project into libraries and using package managers, such as conan.
Similar to membranes of cells, skins of animals, canopy and edges of forests, forests of Earth, so is the interface of opaque modules.

